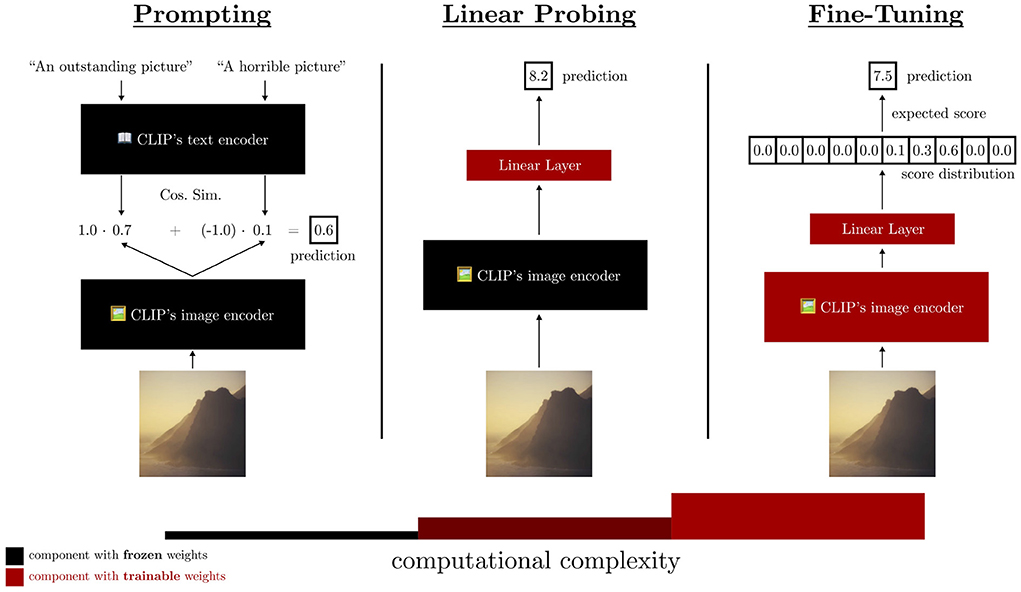
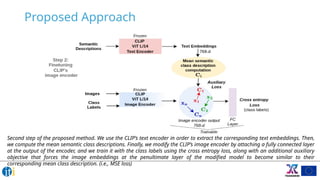
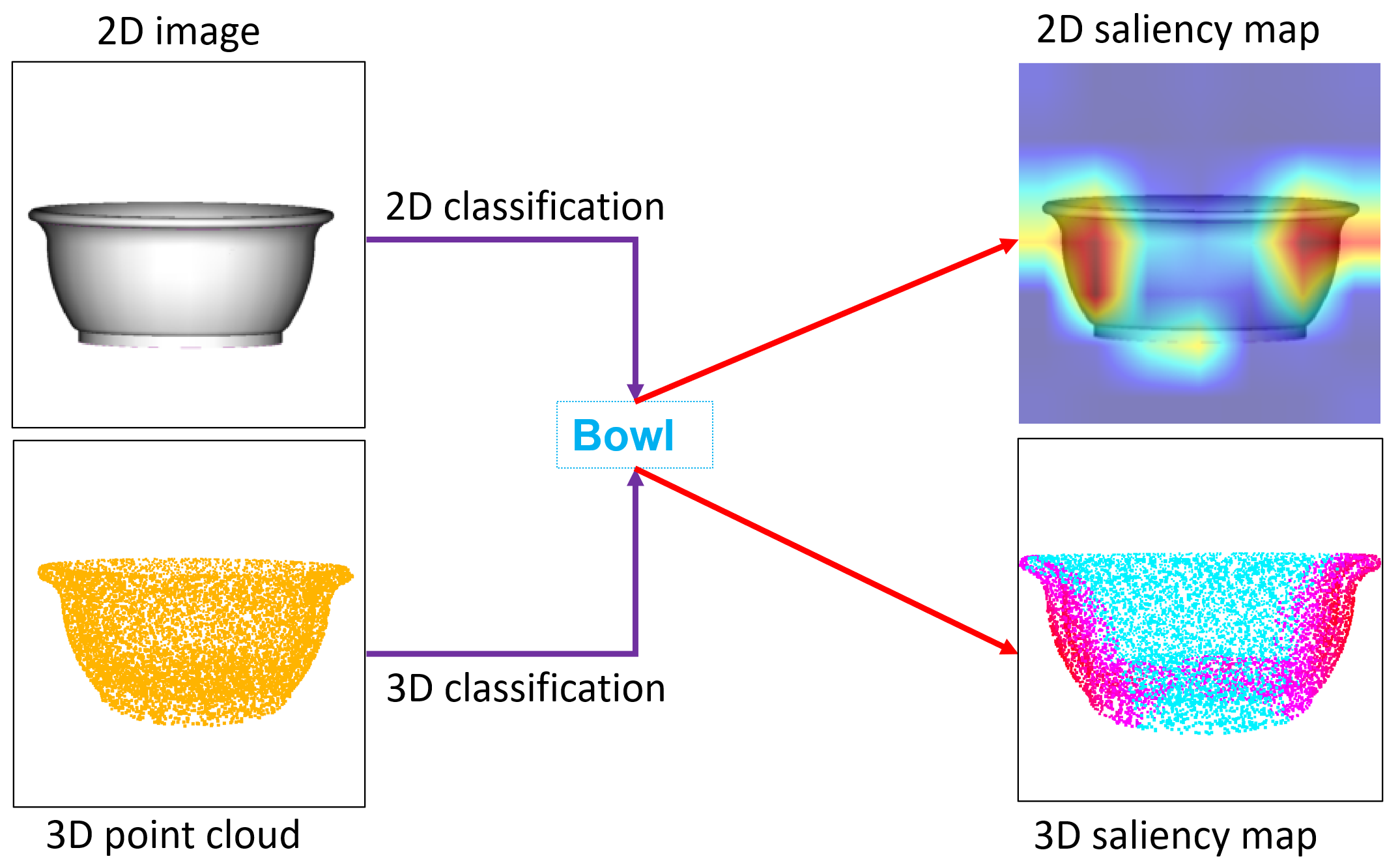
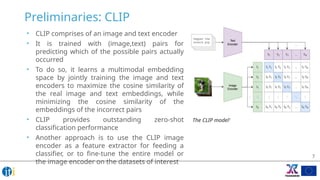
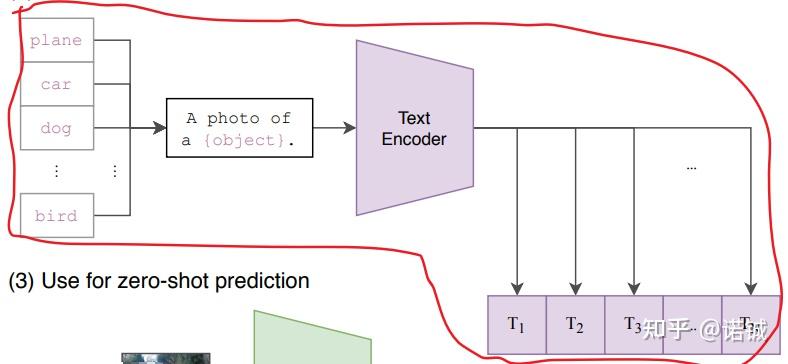
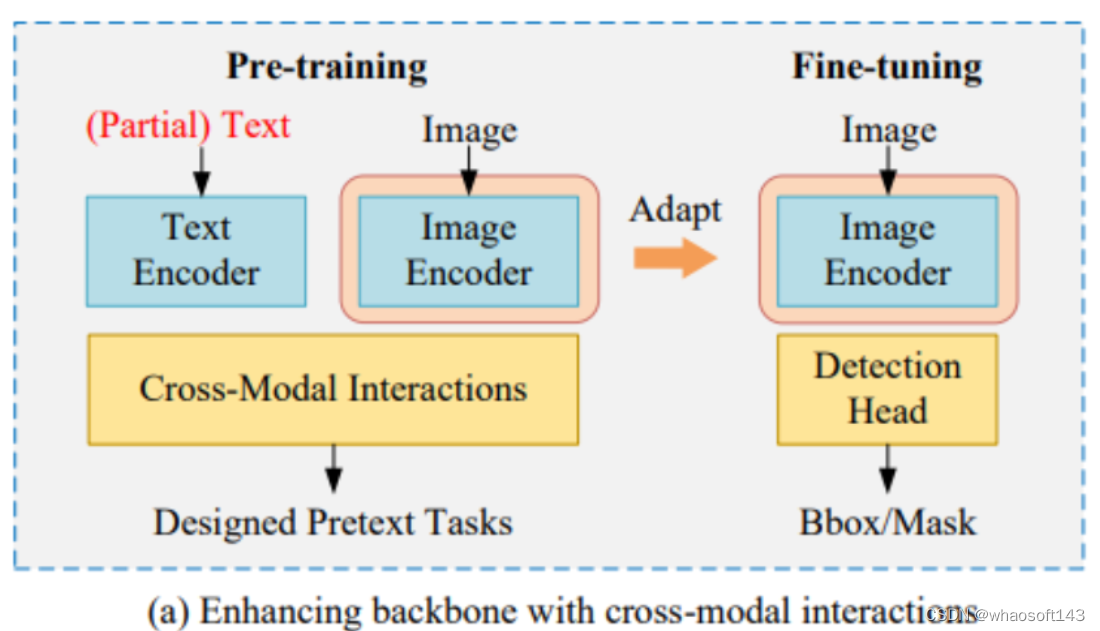
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
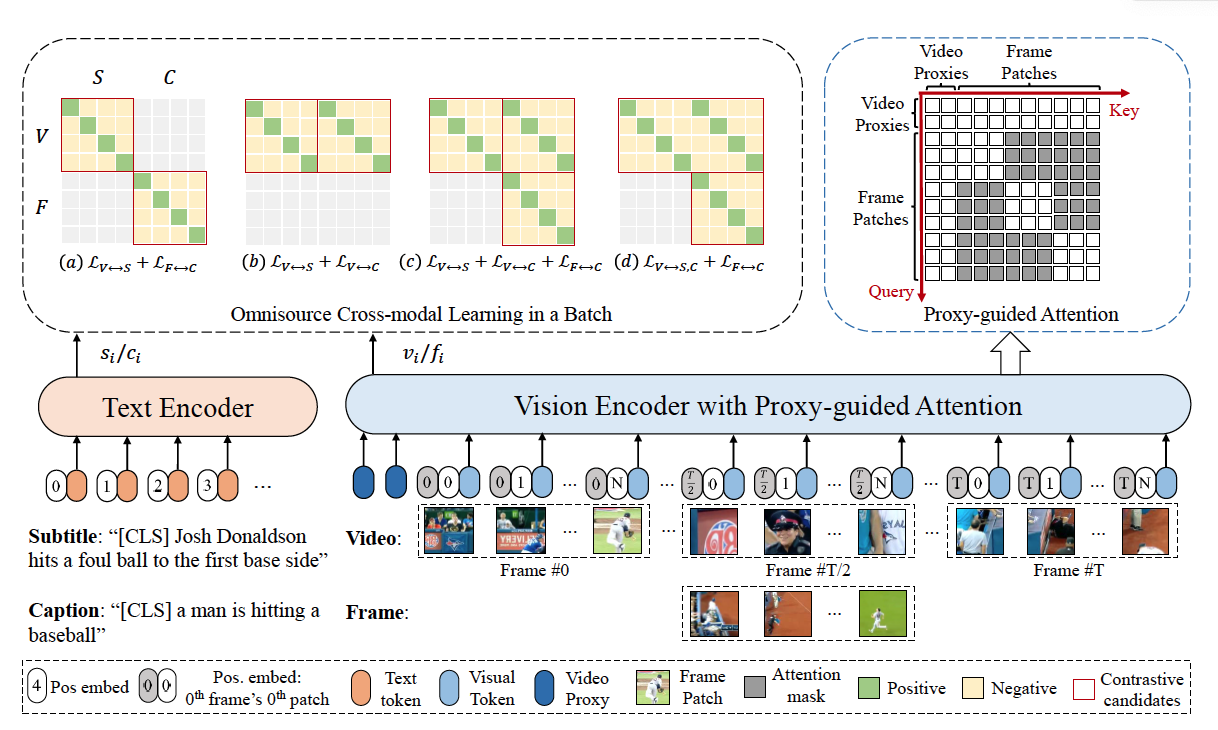
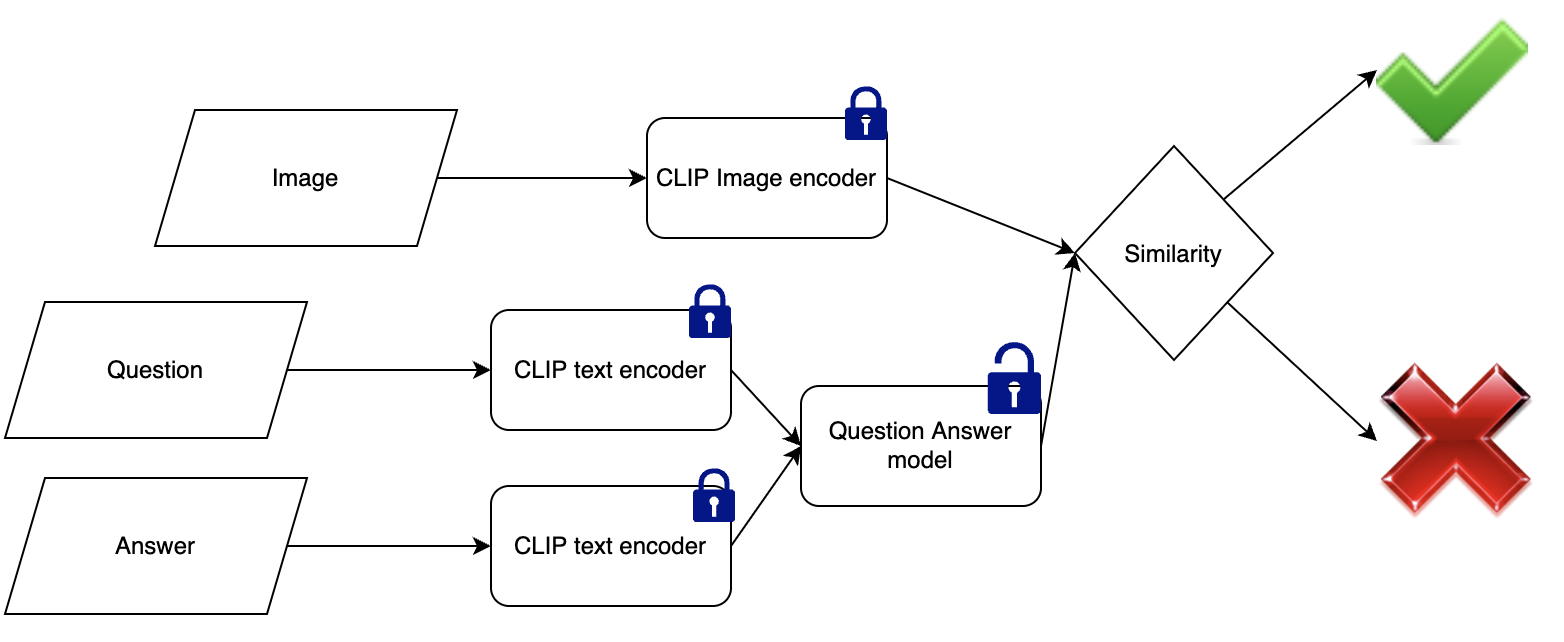
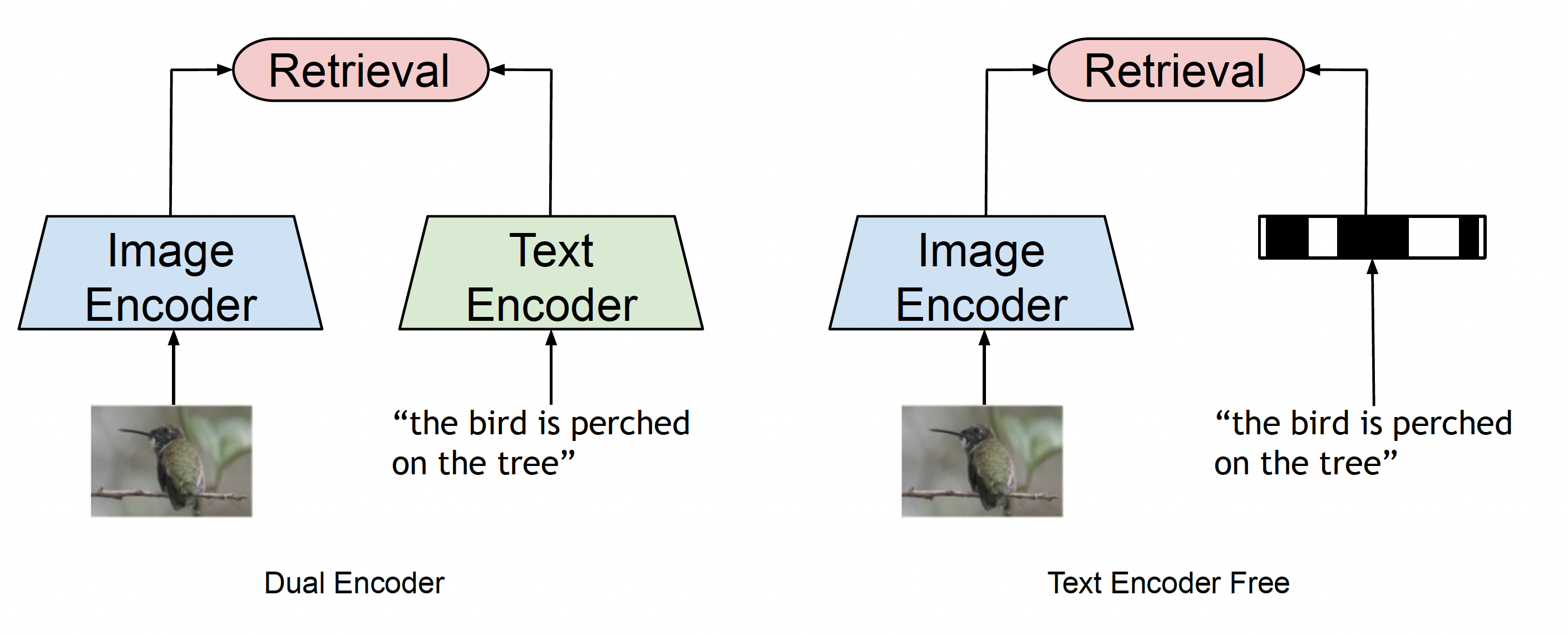
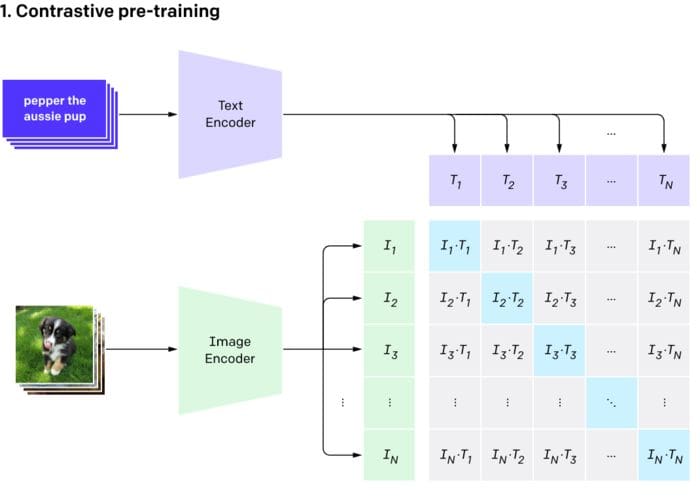
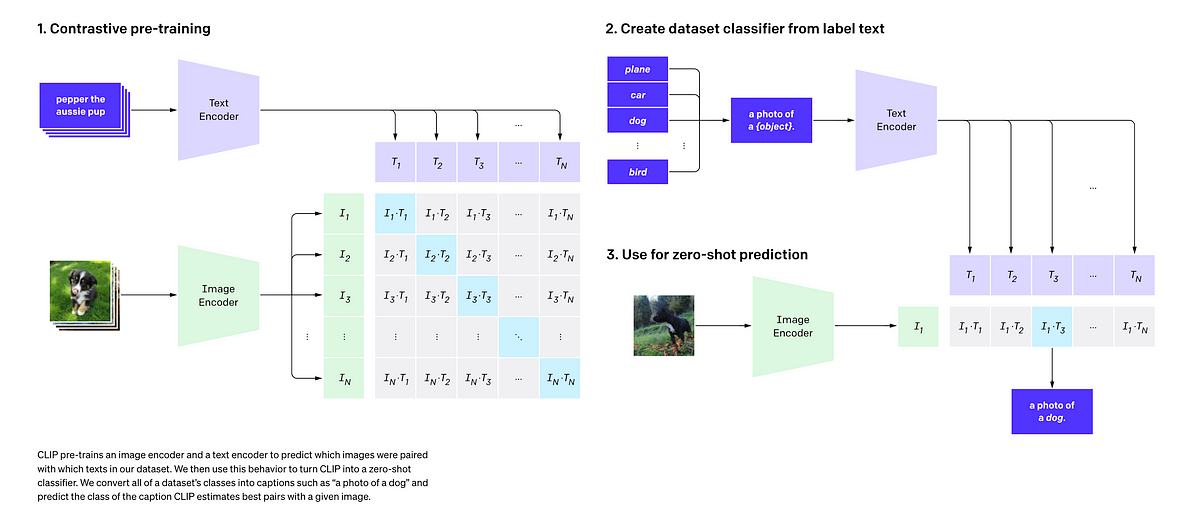
Image–Text Matching Model Based on CLIP Bimodal Encoding
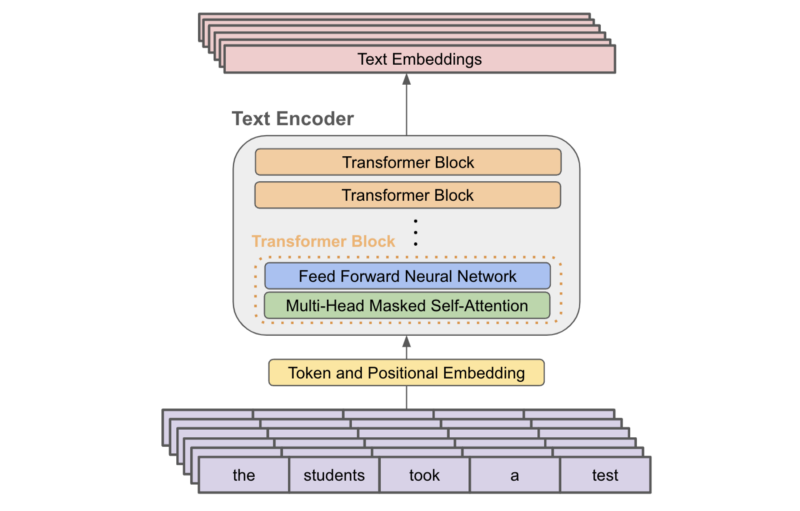
Text as Guidance for Diffusion Models - CLIP Text Encoder - deeplizard
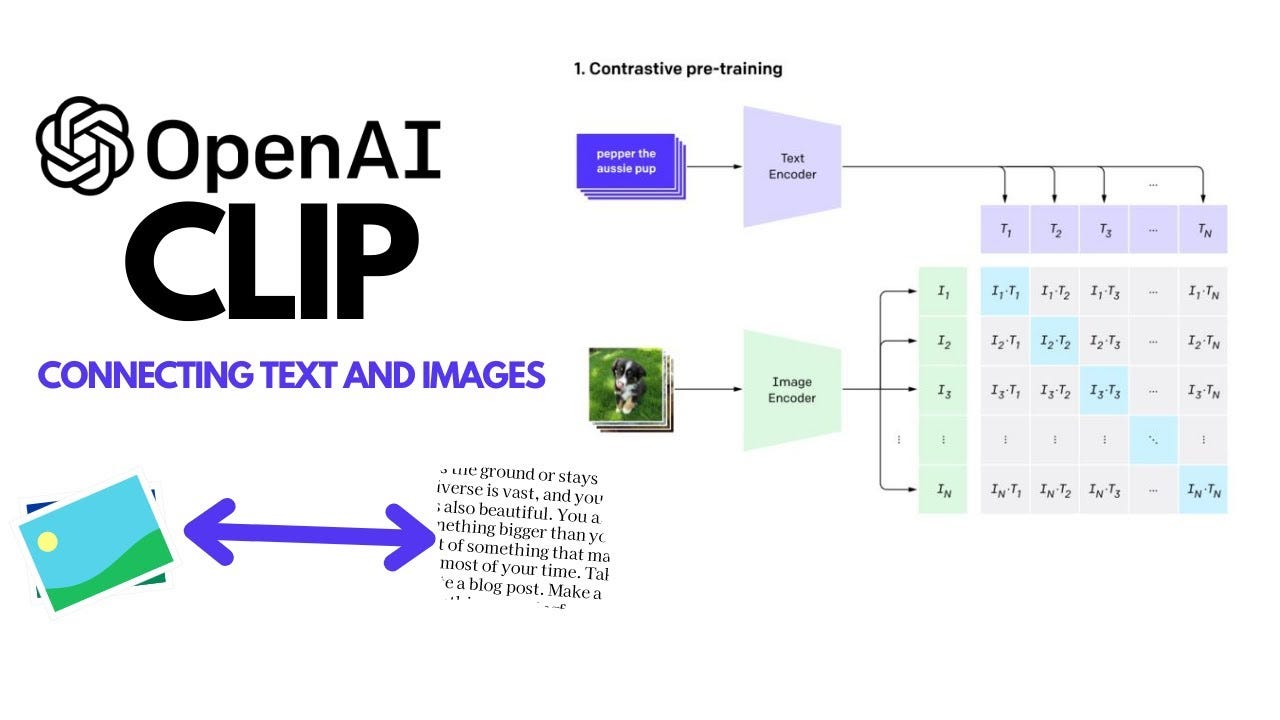
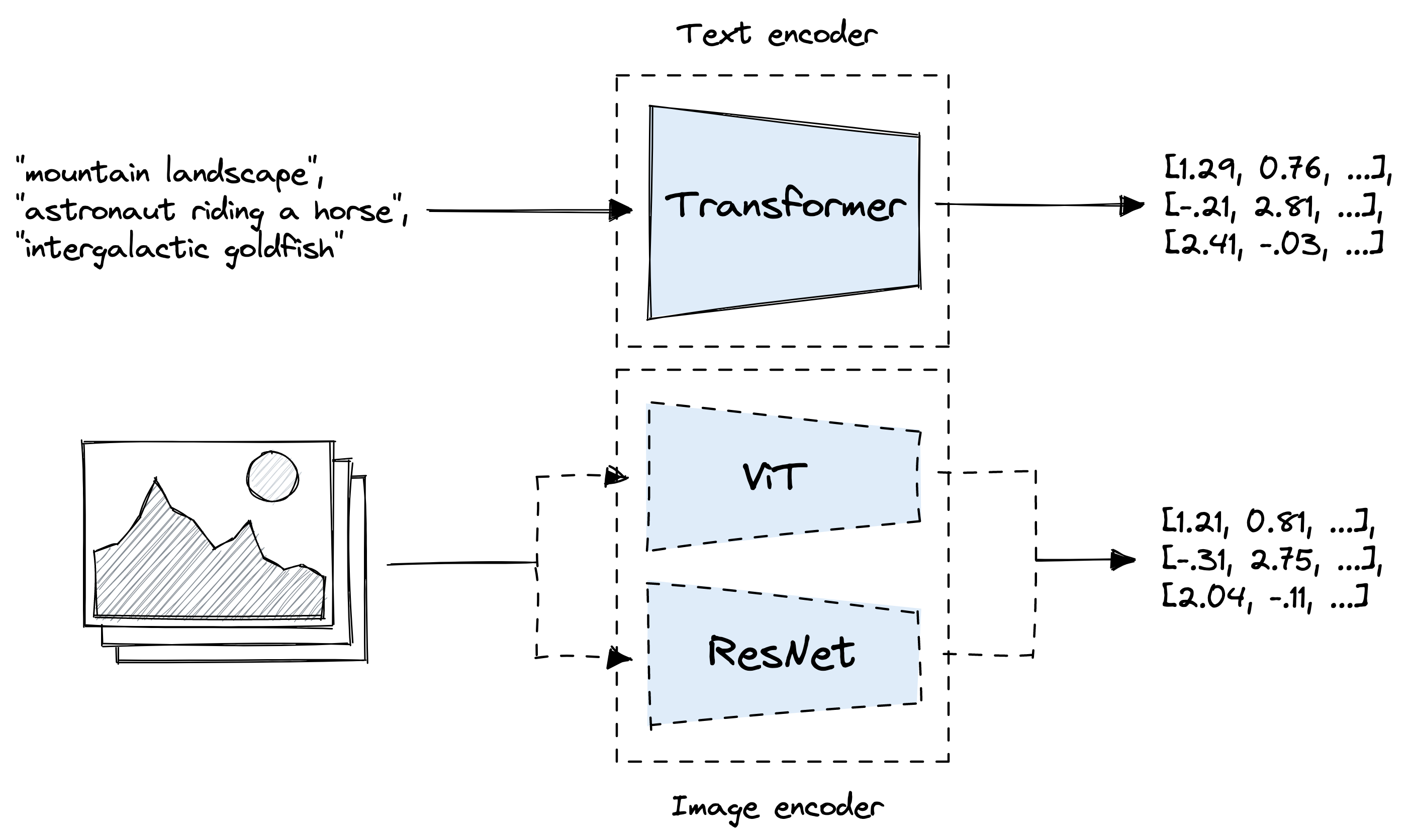
Example showing how the CLIP text encoder and image encoders are used ...
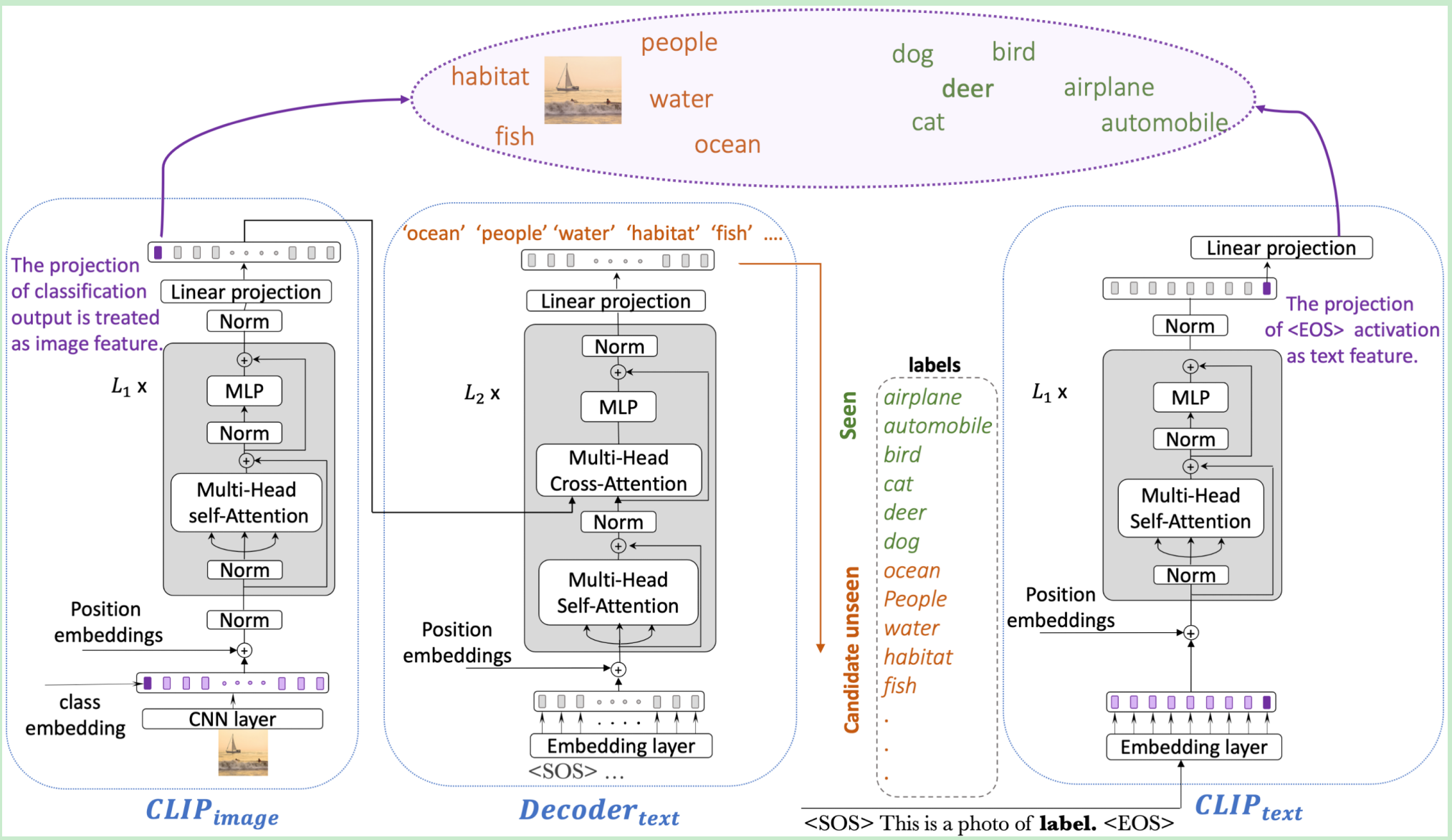
Overview of our proposed KKLIP. KKLIP has six models: CLIP text encoder ...
(PDF) Turning a CLIP Model into a Scene Text Detector
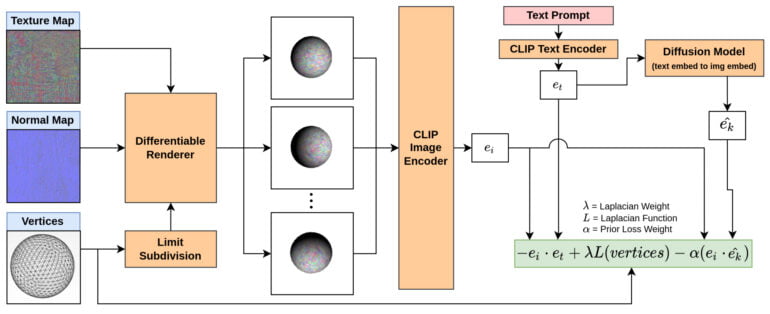
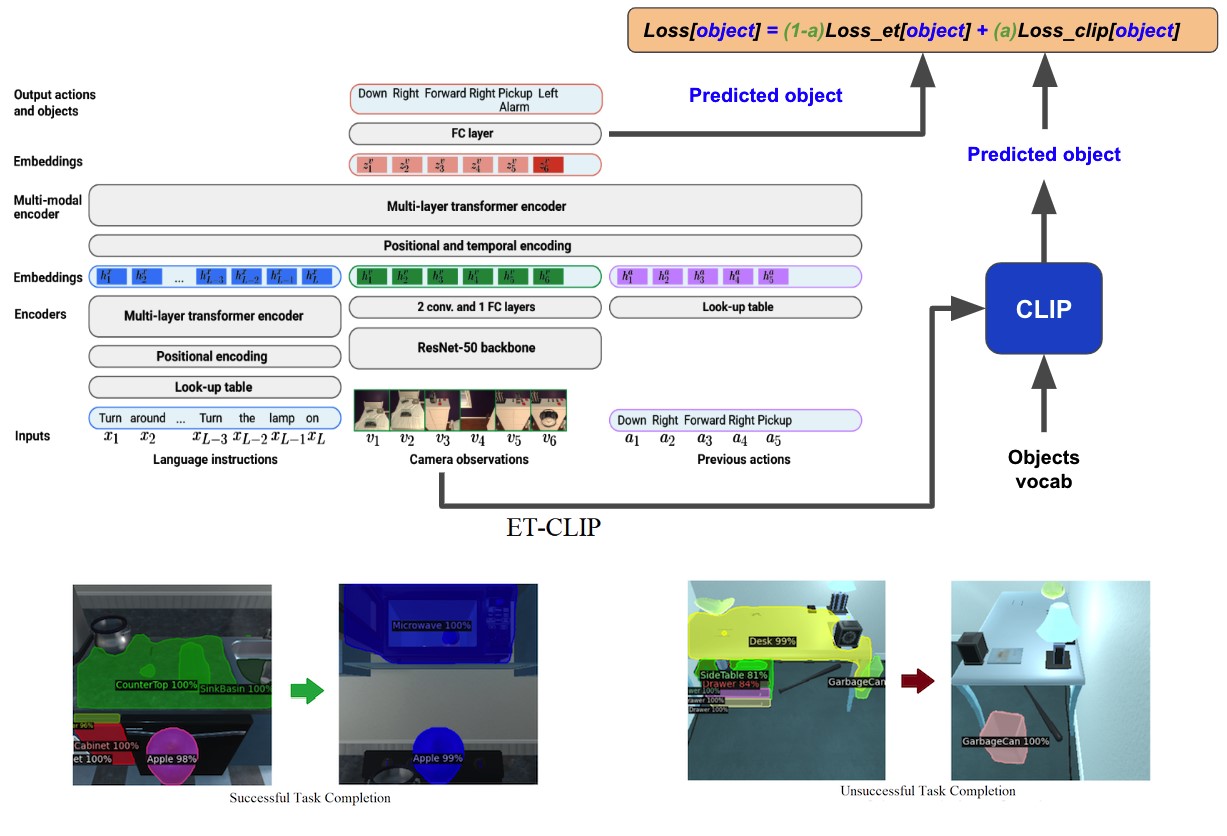
Process diagram of the CLIP model for our task. This figure is created ...
(PDF) Turning a CLIP Model into a Scene Text Spotter
【论文阅读】Turning a CLIP Model into a Scene Text Detector-CSDN博客
MLX CLIP Text Encoder
GitHub - tanwanirahul/CLIP_from_scratch: OpenAI's CLIP model ...
Google Clip Model at Francis Needham blog
A Beginner’s Guide to the CLIP Model - KDnuggets
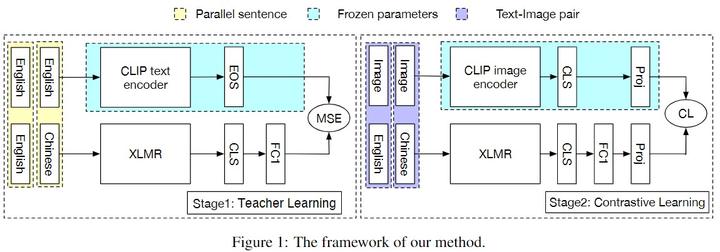
【论文精读04】AltCLIP: Altering the Language Encoder in CLIP for Extended ...
What Is Encoder Decoder Model at Qiana Flowers blog
Understanding OpenAI’s CLIP model | by Szymon Palucha | Medium
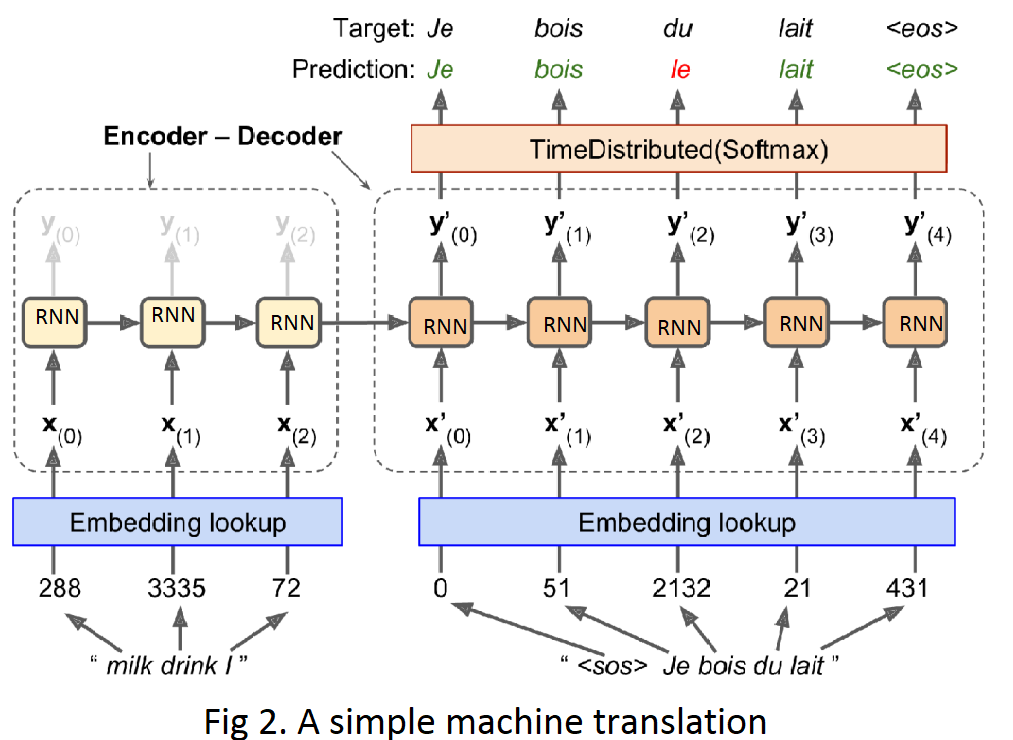
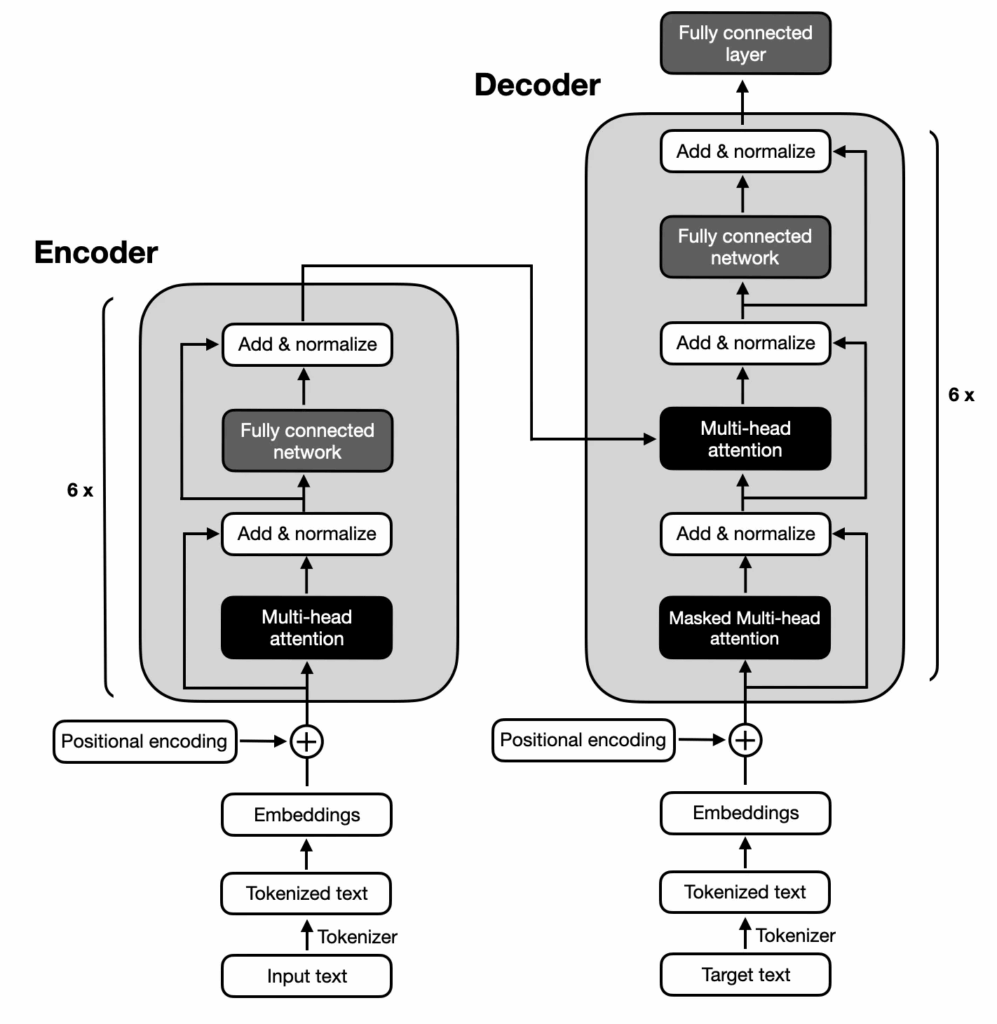
Transformer Model — Encoder and Decoder | by LEARNMYCOURSE | Medium
Train a CLIP model on CIFAR 10. VIT encoder, Pretrained Resnet vision ...
Why is there a difference in the text encoder between CLIP and open ...
CLIP Model and The Importance of Multimodal Embeddings | Towards Data ...
The framework of Re-ViLM. The model first extracts CLIP embedding of ...
Performance for the CLIP visual encoder using a ResNet backbone as ...
Model encoder dan encoder-decoder fleksibel dan bisa melakukan banyak ...
We use CLIP image encoder for the images, with the left side ...
The encoder model similarity matrix, showing confident matches along ...
Illustrative concepts and an example input on a CLIP model (Radford et ...
| Schematic of Model Encoder | Download Scientific Diagram
Testing Perception Encoder vs CLIP on COCO and RF100-VL using identical ...
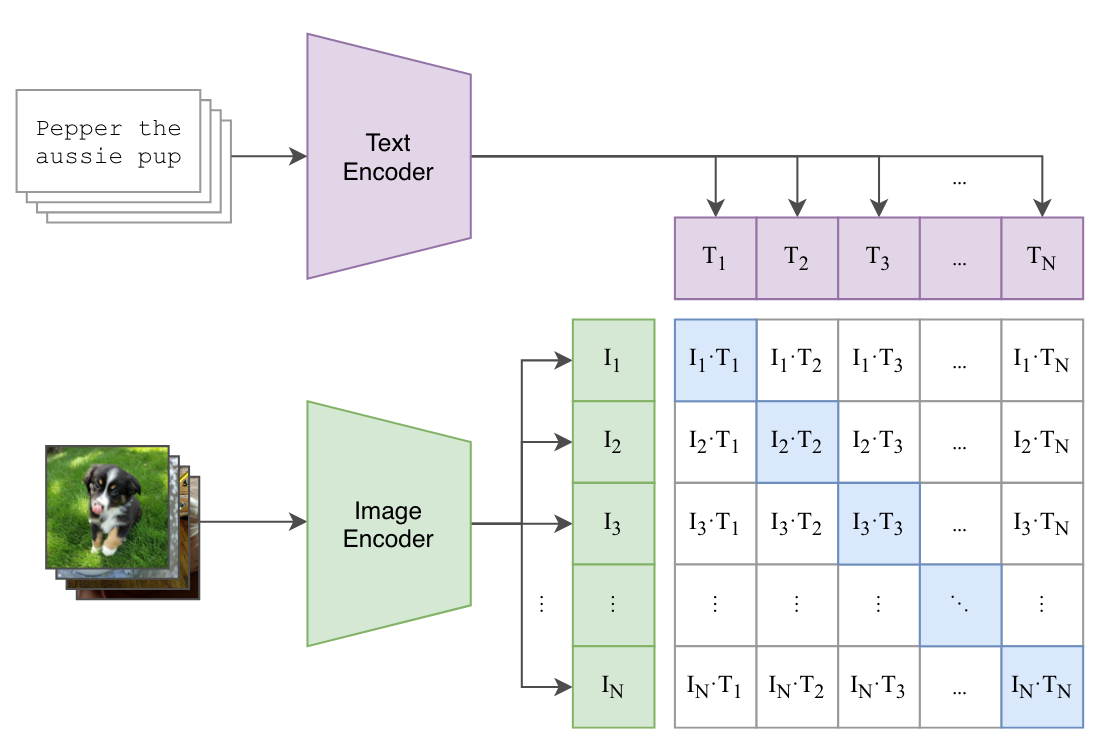
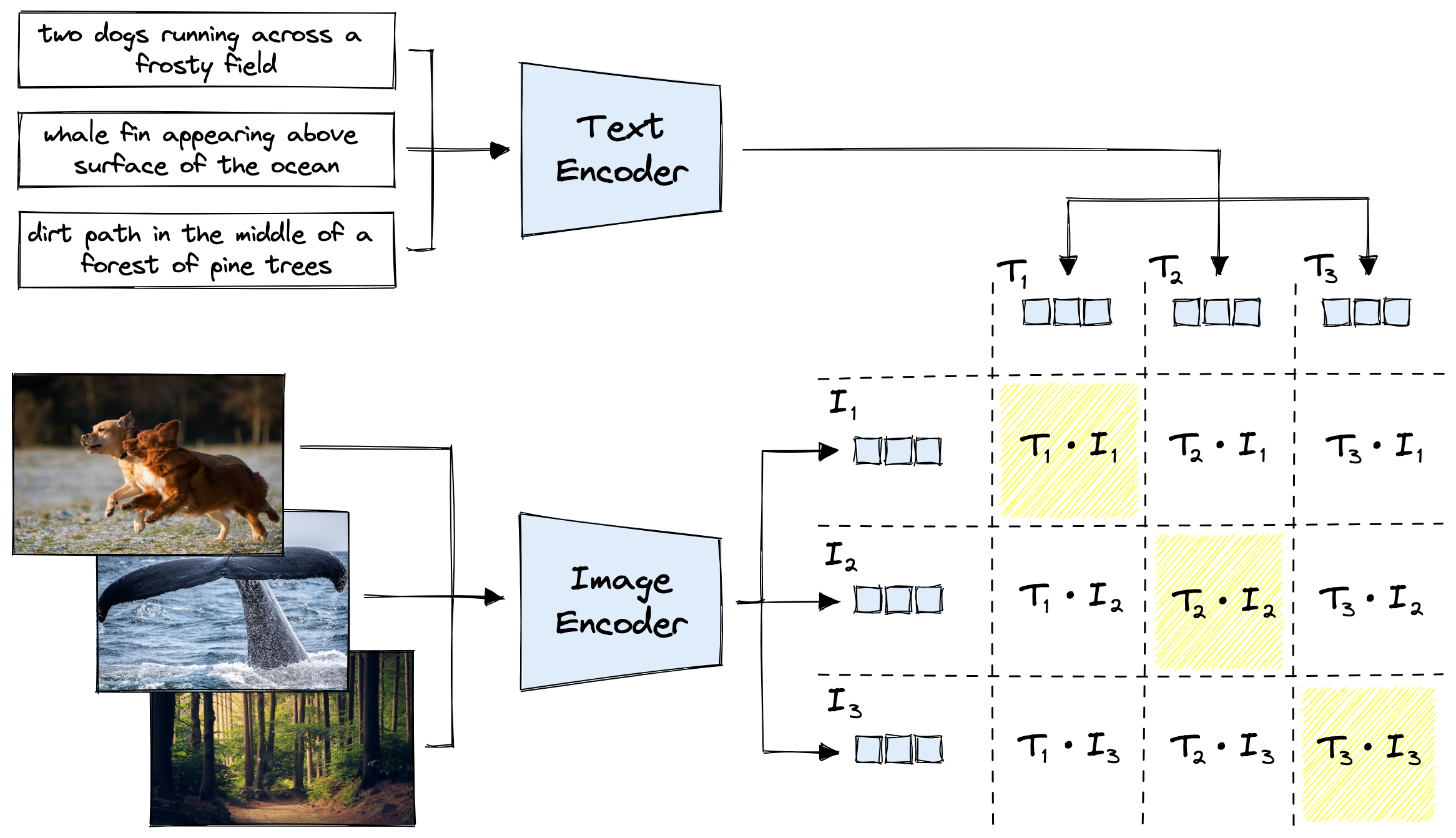
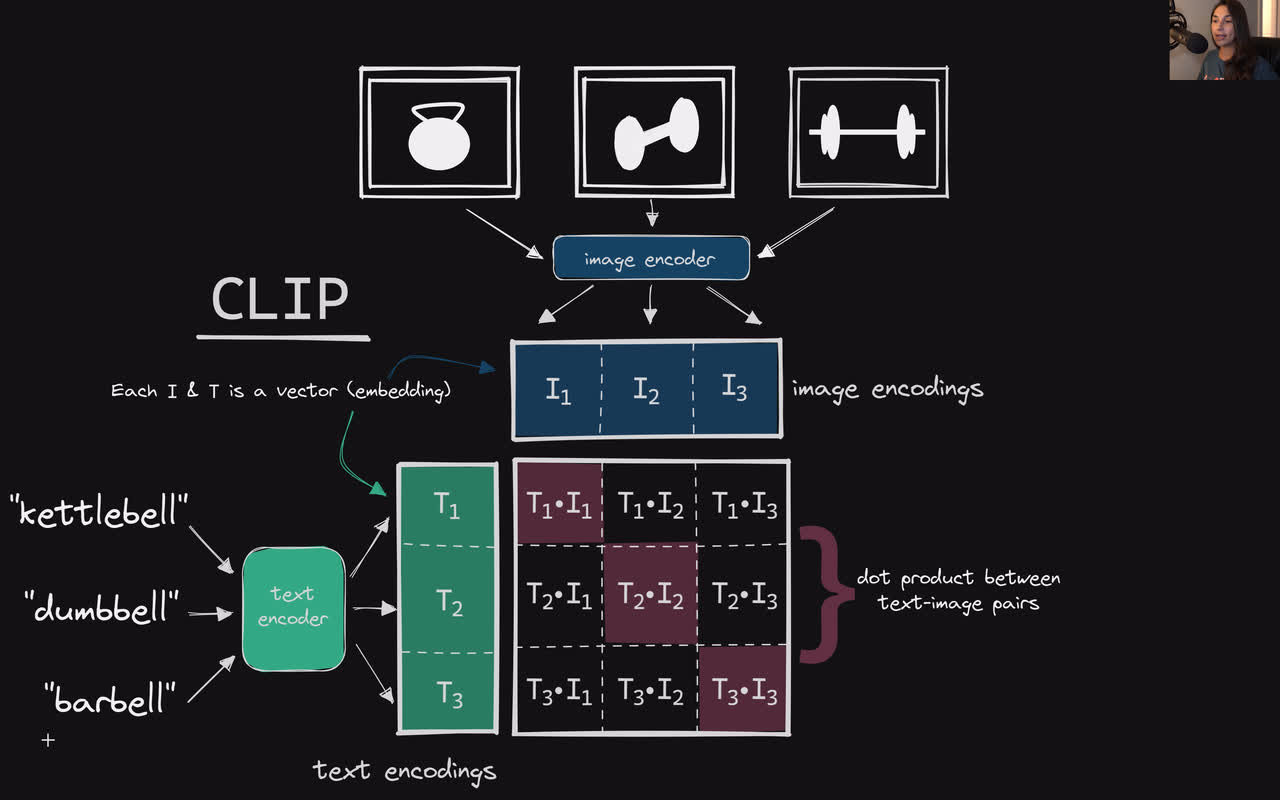
Multi-modal ML with OpenAI's CLIP | Pinecone
Bridging the Gap Between Text and Images in Computer Vision With CLIP ...
Workflow of the CLIP Model, highlighting its key components and the ...
Stable Diffusion核心网络结构——CLIP Text Encoder - 技术栈
Clip Architecture Definition at Tracy Macias blog
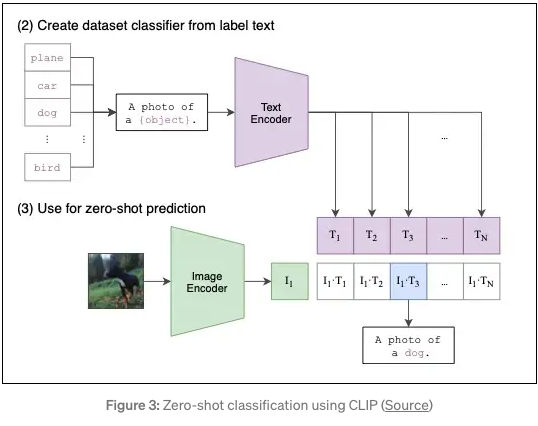
CLIP (Contrastive Language-Image Pretraining) - GeeksforGeeks
Overview of VT-CLIP where text encoder and visual encoder refers to the ...
[MultiModal] CLIP-ViP: Adapting Pre-trained Image-Text Model to Video ...
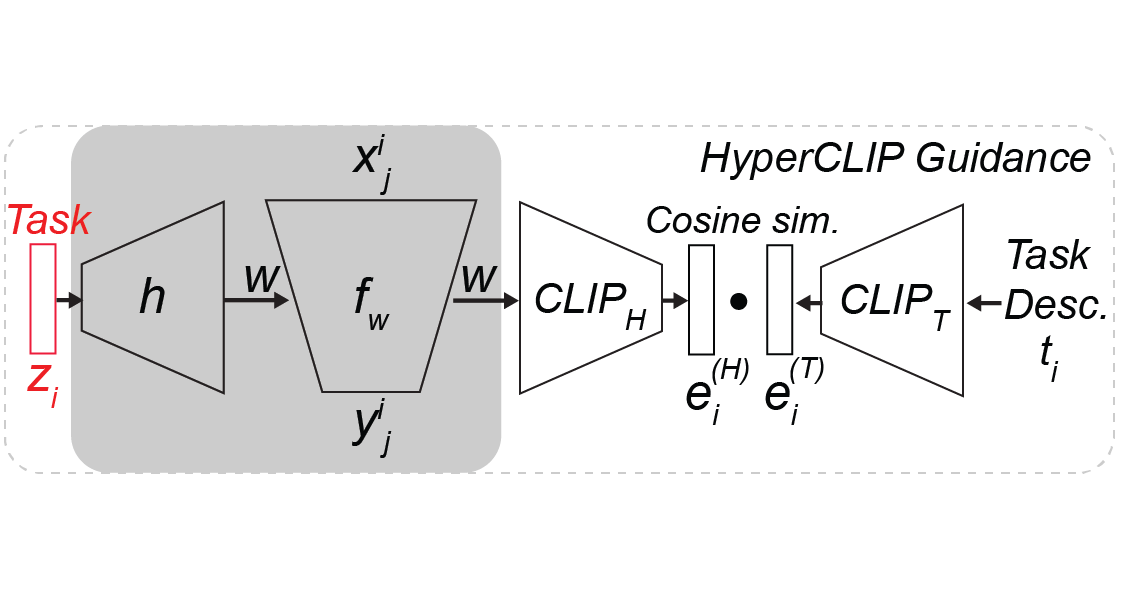
You've all seen CLIP guidance and diffusion models used for language ...
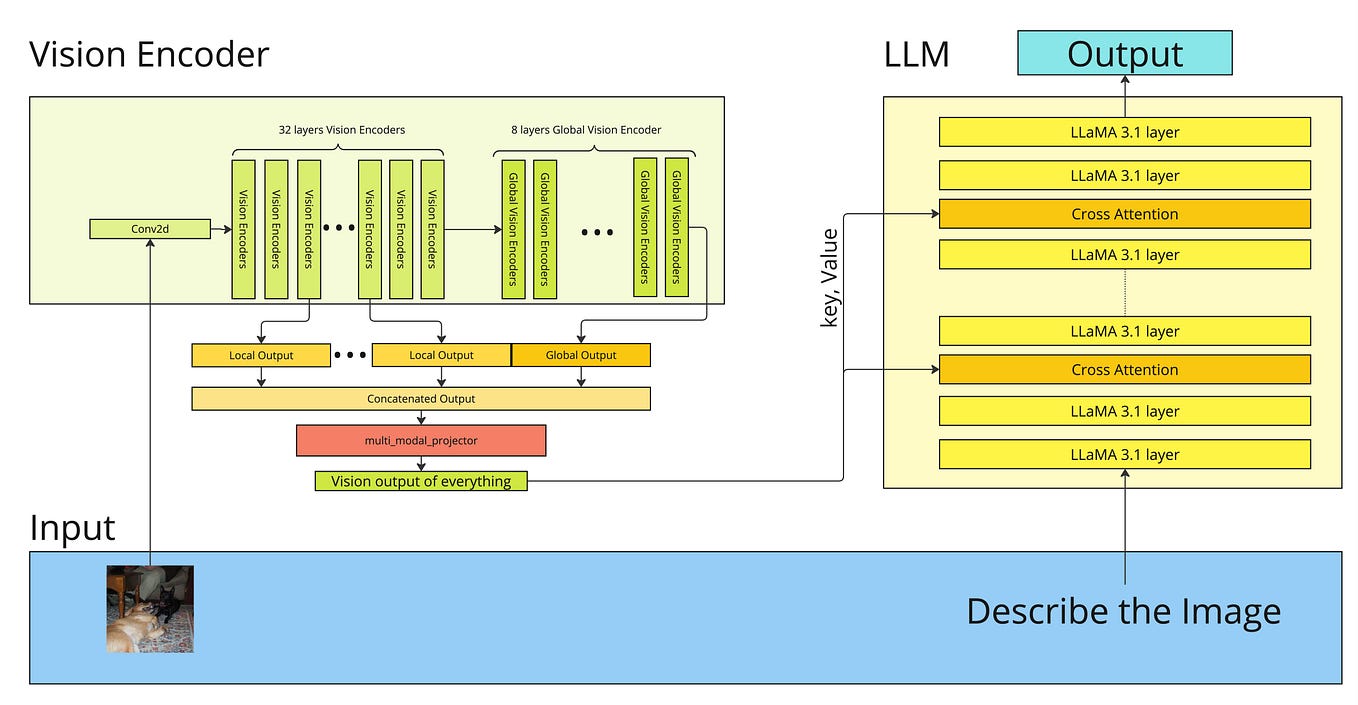
A Guide to Implement the Vision Encoder for LLaVA | Medium
The Annotated CLIP (Part-2)
Method 1/2 for using CLIP in domain. Specifically, the text/image ...
Comparisons of frameworks based on CLIP models for image... | Download ...
What Is An Encoder And A Decoder at Oliver Silas blog
Qualitative results of the X-CLIP model without vs with the pretrained ...
Unlocking the Power of CLIP Encoder: A Text Encoder's Impact
Stable Diffusion 源码学习2 - Text Encoder - 知乎
This diagram illustrates, the methods we use to adopt the CLIP ...
Understanding CLIP: OpenAI’s Breakthrough Model for Image and Text ...
An overview of the material and clip sequence encoders | Download ...
New CLIP-L Text Encoder for Flux.1 — Better Prompt Quality
Visual Question Answering using CLIP - Ashwin’s
The model architecture details of encoders in Vitals-CLIP. The inner ...
【论文笔记】Fine-tuned CLIP Models are Efficient Video Learners-CSDN博客
Multi-Task Video Captioning with a Stepwise Multimodal Encoder
CLIP Text Encoder-CSDN博客
Proposed approach of CLIP with Multi-headed attention/Transformer ...
ModernBERT: The Next Generation of Encoder Models — A Guide to Using ...
Aman's AI Journal • Models • CLIP
Encoder-decoder model structure. | Download Scientific Diagram
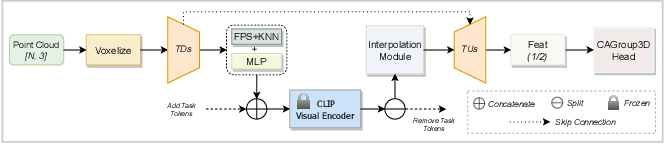
Figure 10 from Frozen CLIP Transformer Is an Efficient Point Cloud ...
CLIP: The Most Influential AI Model From OpenAI — And How To Use It ...
Frontiers | CLIP knows image aesthetics
LMM-Regularized CLIP Embeddings for Image Classification | PPT
[2212.04098] EPCL: Frozen CLIP Transformer is An Efficient Point Cloud ...
Encoder-Decoder model combined with attention mechanism | Download ...
What is BERT (Bidirectional Encoder Representations from Transformers ...
LMM-Regularized CLIP Embeddings for Image Classification | PPTX
Using different encoders in CLIP · Issue #12 · lucidrains/x-clip · GitHub
Stable Diffusion核心网络结构——CLIP Text Encoder-CSDN博客
CLIP-Mesh: AI generates 3D models from text descriptions
Overview of our method. The image is encoded into a feature map by the ...
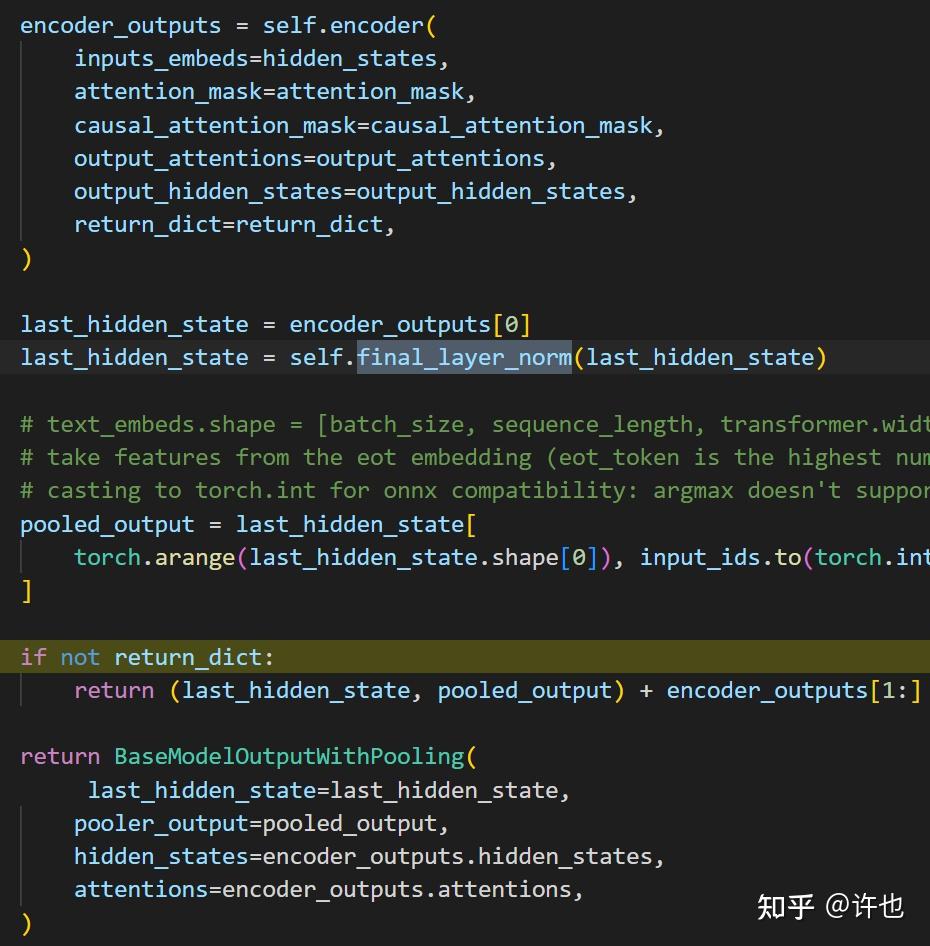
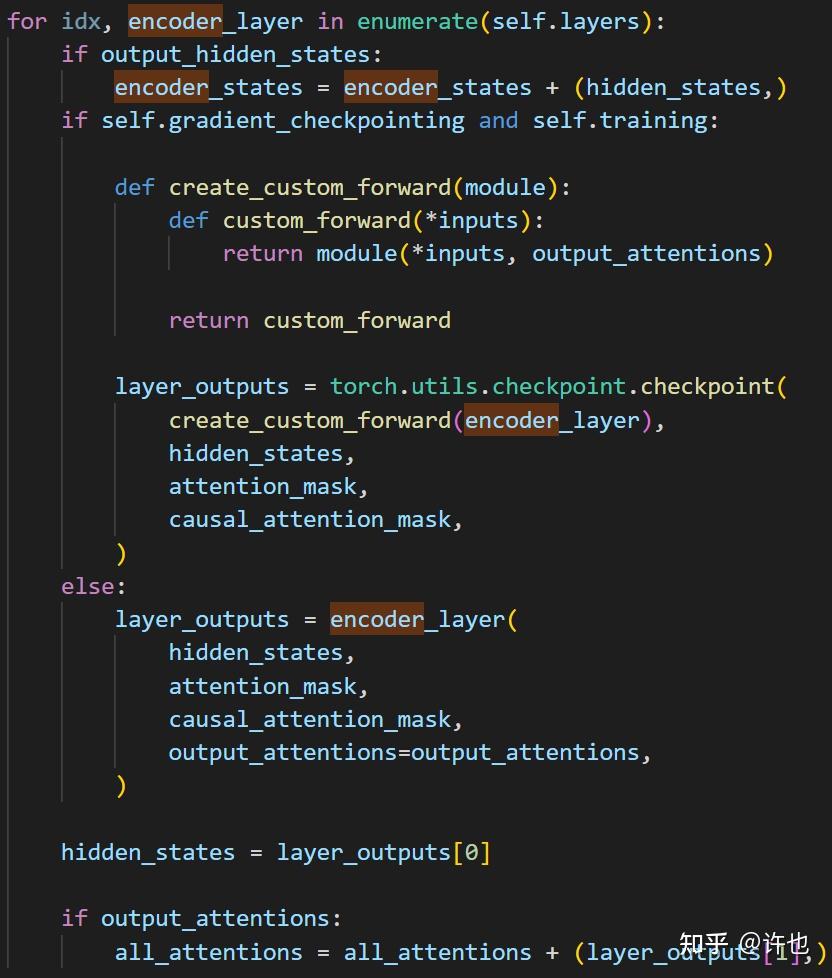
CLIP/clip/model.py at main · openai/CLIP · GitHub
Vision Transformers: From Idea to Applications (Part Four)
MotionCLIP overview. A motion auto-encoder is trained to simultaneously ...
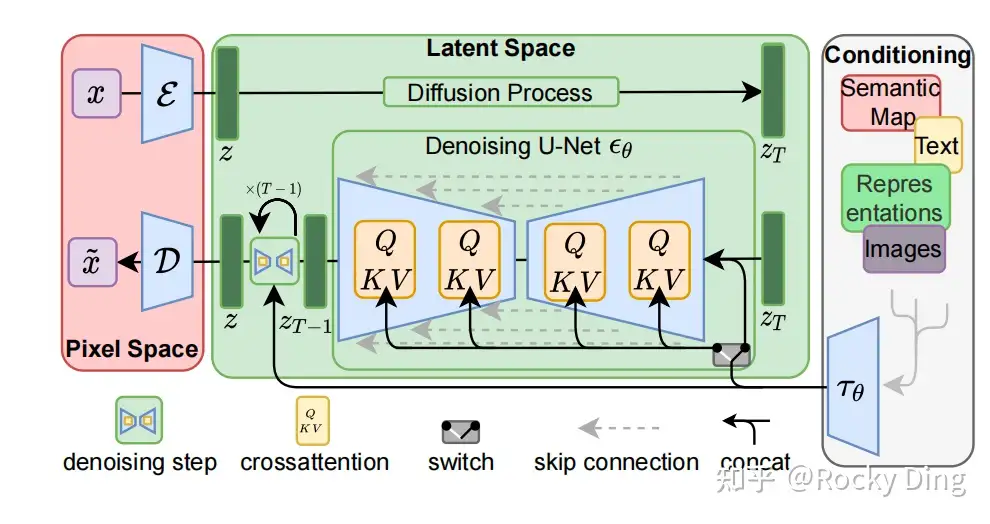
深入浅出完整解析Stable Diffusion(SD)核心基础知识 - 知乎
ComfyUI Beginner's Ultra-Detailed Guide - ComfyUI Учебники - Узнайте ...
LaraSg/CLIP-en-text-encoder at main
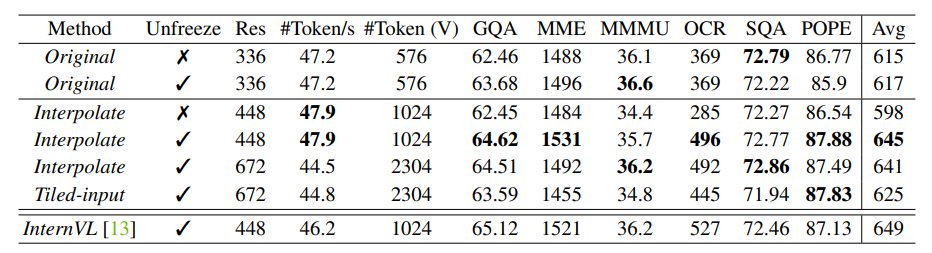
EAGLE: Exploring the Design Space for Multimodal Large Language Models ...
FasterVLM/llava/model/multimodal_encoder/clip_encoder.py at main ...
[2301.13081] STAIR: Learning Sparse Text and Image Representation in ...
Architecture of HOICLIP. Given an image, HOICLIP encodes it with a ...
Microsoft Released LLM2CLIP: A New AI Technique in which a LLM Acts as ...
Deep Dive into Encoder-Decoder Architecture: Theory, Implementation and ...
Shahriar Noroozizadeh, ML PhD at CMU
CLIP-RL: Surgical Scene Segmentation Using Contrastive Language-Vision ...
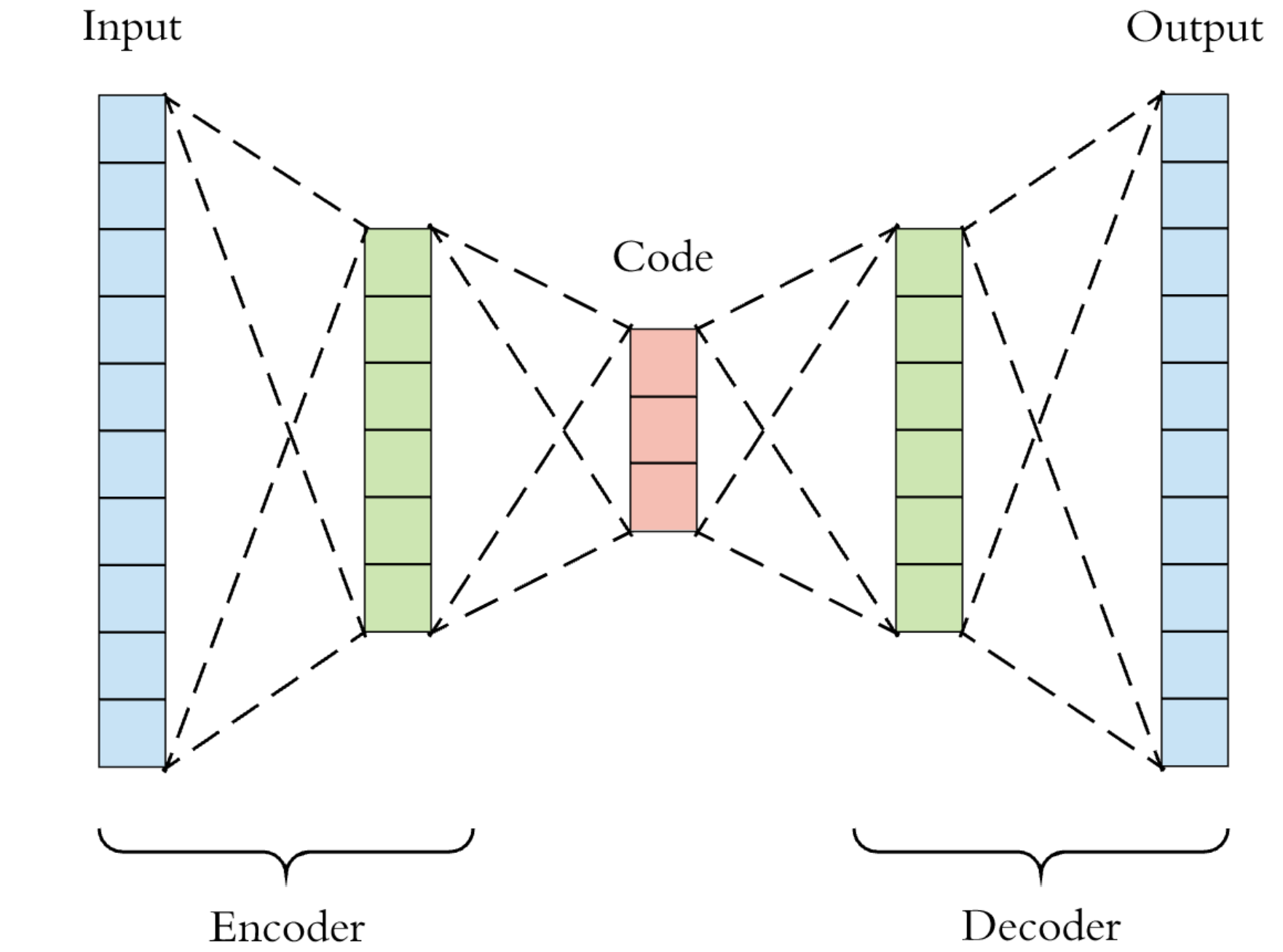
Encoder-Decoder Models - Naukri Code 360
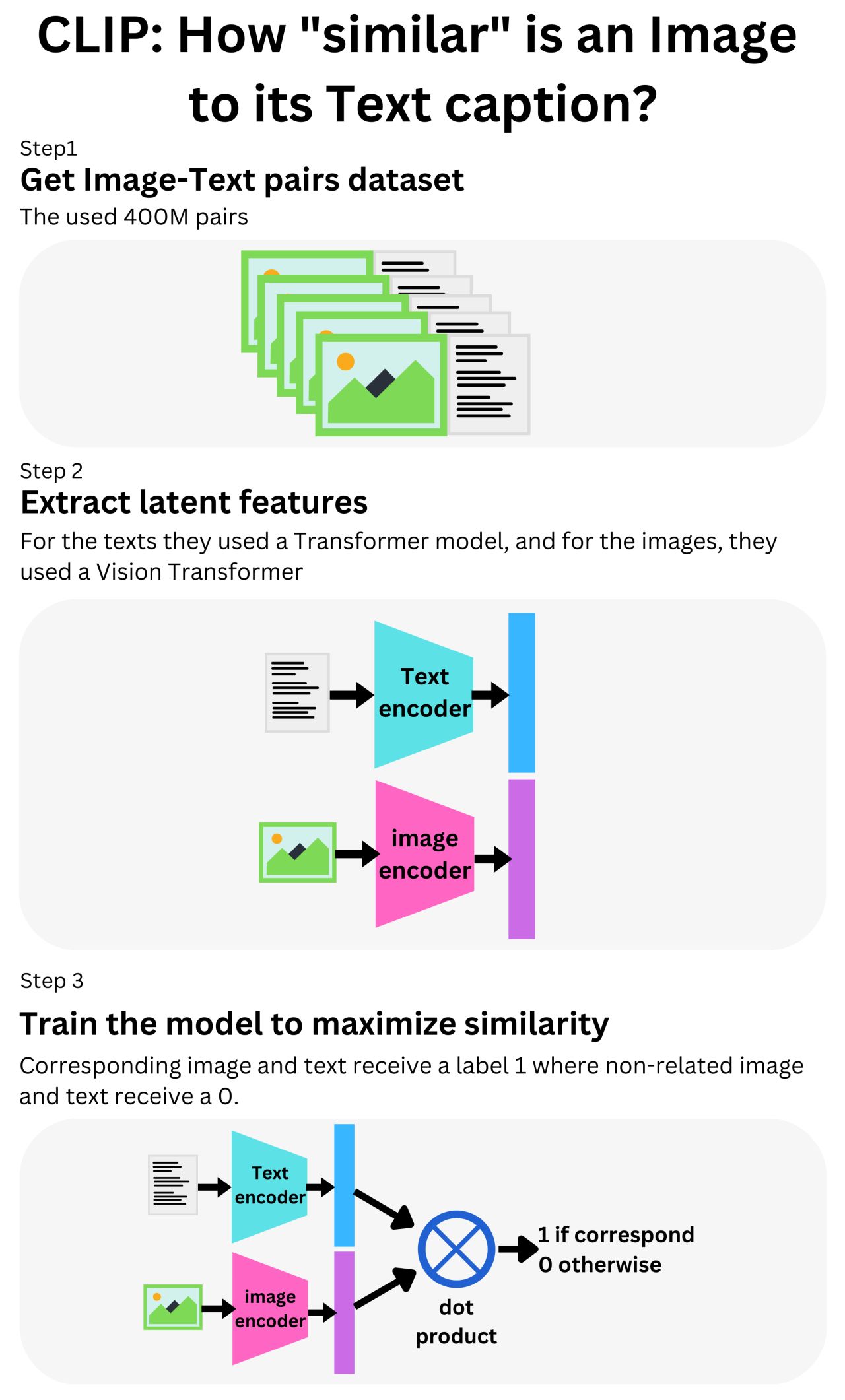
CLIP, Intuitively and Exhaustively Explained | Towards Data Science
Hướng dẫn cài đặt Flux - ComfyUI để tạo ảnh AI
多模态CLIP详解与使用 - 知乎
GitHub - saadkh1/clip_dual_encoder: Visual and Vision-Language ...
A Comprehensive Overview of Transformer-Based Models: Encoders ...
CLIP6-CSDN博客
Encoders-Only Models: Workhorses of Practical Language Processing ...
How AI Art Works? - Everything You Need to Know
Transformer based Encoder-Decoder models for image-captioning on AMD ...
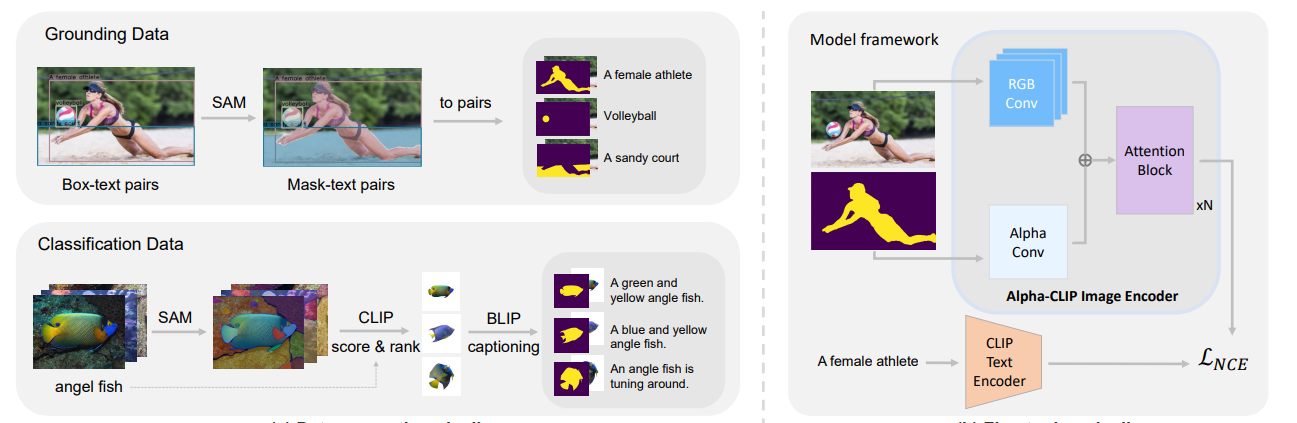
Architecture of our robust CLIP-based image encoder, which combines ...
What is CLIPSeg & how we build optimization pipelines for text-guided ...
CLIP2-CSDN博客
zer0int/clip-vit-large-patch14-336-text-encoder at main
【论文笔记】CLIP:Learning Transferable Visual Models From Natural Language ...
CLIP模型系列 - 知乎
Memory Reviving, Continuing Learning and Beyond: Evaluation of Pre ...





















.png)